
In [2]:
import numpy as np
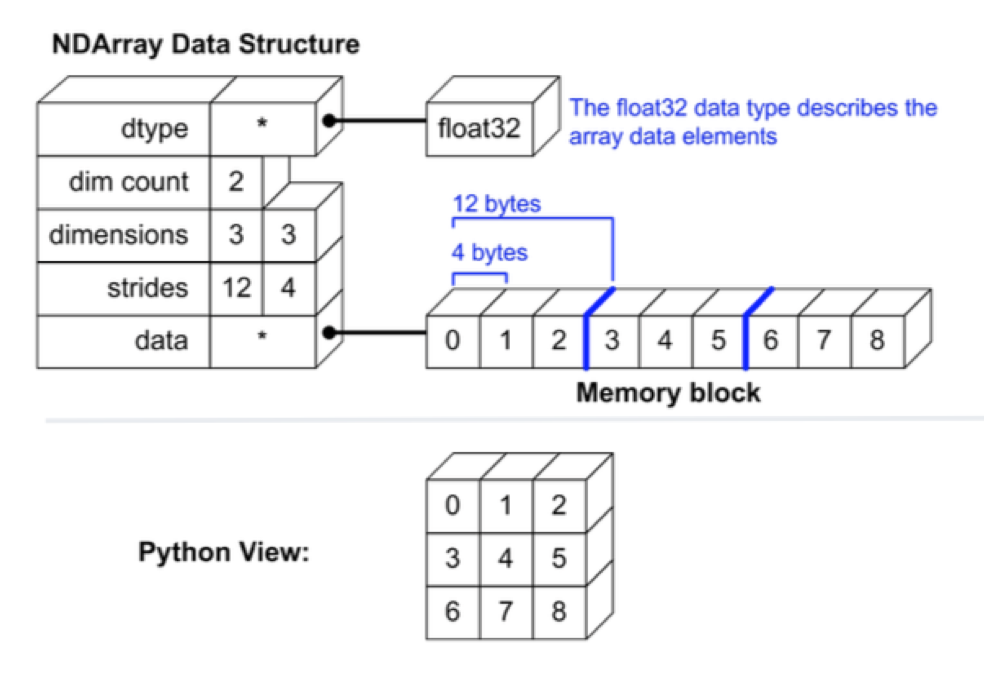
NumPy 和 SciPy¶

Numpy基础是数组对象ndarray
- 数组的列类型是一致的
Numpy 数据类型¶
np.dtype
- bool
- inii
- int8
- int16
- int32
- int64
- uint8
- uint16
- uint32
- uint64
- float16
- float32
- float64, float
- complex128, complex
字符编码
- i 整数
- u 无符号整数
- f 浮点
- d 双精度浮点
- b bool
- D 复数
- S 字符串
- U unicode字符串
- V 空
In [3]:
np.dtype('i'), np.dtype(float)
Out[3]:
In [4]:
t = np.dtype('Float64')
t.char, t.type
Out[4]:
创建 np.array 数组¶
In [5]:
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
a
Out[5]:
In [6]:
b = np.arange(10, dtype=np.int8)
b
Out[6]:

In [7]:
val = np.array([5, 12, 2, 32, 19, 71, 48])
val[1:5:2]
Out[7]:

In [8]:
# fancy indexing
a = np.arange(1,16).reshape(3,5)
a
Out[8]:
In [9]:
a[[1,2]]
Out[9]:
In [10]:
a[[1,2], [3, 4]]
Out[10]:
In [11]:
a[a>5]
Out[11]:
In [12]:
# 生成函数
x = np.arange(-10,10,2)
x
Out[12]:
In [13]:
x = np.linspace(-10, 10, 20)
x
Out[13]:
In [14]:
y = np.logspace(0, 10, 20, base=np.e)
y
Out[14]:
In [15]:
# similar to meshgrid in MATLAB
x, y = np.mgrid[0:5, 0:5]
In [16]:
x
Out[16]:
In [17]:
# uniform random
np.random.rand(5,5)
Out[17]:
In [18]:
# 正态分布
np.random.randn(5,5)
Out[18]:
np.array 操作¶
In [19]:
a.shape = (3,4)
a
In [20]:
a.reshape(5,3)
Out[20]:
In [21]:
# 展平
b = a.ravel()
In [22]:
a
Out[22]:
In [23]:
b
Out[23]:
In [24]:
b = a.flatten()
In [25]:
a
Out[25]:
In [26]:
b
Out[26]:
ravel返回的是视图,而flatten返回的是重新分配内存的新结果
In [27]:
a
Out[27]:
In [28]:
a.transpose()
Out[28]:
In [29]:
a
Out[29]:
In [30]:
a.T
Out[30]:
In [31]:
a.resize((5,3))
In [32]:
a
Out[32]:
与reshape不同,它就地更新结构
In [33]:
a.ndim
Out[33]:
In [34]:
a.size
Out[34]:
In [35]:
a.itemsize
Out[35]:
In [36]:
a.nbytes
Out[36]:
In [37]:
a.dtype
Out[37]:
In [38]:
a.T
Out[38]:
In [39]:
a.tolist()
Out[39]:
In [40]:
a.dot(a.T)
Out[40]:
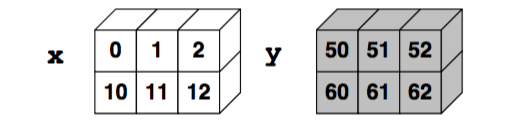
In [41]:
x = np.array([[0, 1, 2],[10, 11, 12]])
y = np.array([[50, 51, 52],[60, 61, 62]])
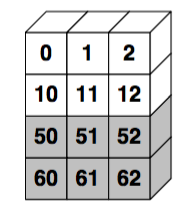
In [42]:
np.concatenate((x, y))
Out[42]:
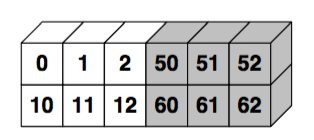
In [43]:
np.concatenate((x, y), 1)
Out[43]:
In [44]:
np.array((x,y))
Out[44]:

In [45]:
np.vstack((x,y))
Out[45]:
In [46]:
np.hstack((x,y))
Out[46]:
In [47]:
np.dstack((x,y))
Out[47]:
In [48]:
A = np.mat('1 2 3; 4 5 6; 7 8 9')
A
Out[48]:
In [49]:
A = np.matrix('1 2 3; 4 5 6; 7 8 9')
A
Out[49]:
In [50]:
A = np.mat(np.arange(1,10).reshape(3,3))
A
Out[50]:
矩阵的计算¶
In [51]:
# 转置矩阵
A.T
Out[51]:
In [52]:
# 逆矩阵
A.I
Out[52]:
In [53]:
# Hermitian
C = np.matrix([[1j, 2j], [3j, 4j]])
C
Out[53]:
In [54]:
C.H
Out[54]:
In [55]:
# 转化成一维
A.A1
Out[55]:
In [56]:
np.linalg.det(A)
Out[56]:
In [57]:
# 单位矩阵
A = np.eye(3)
A
Out[57]:
In [58]:
B = A*10
B
Out[58]:
In [59]:
np.bmat("A B; B A")
Out[59]:
In [60]:
# 零矩阵
A = np.zeros((3,3))
A
Out[60]:
In [61]:
A = np.mat(np.arange(1,10).reshape(3,3))
B = np.zeros_like(A)
B
Out[61]:
In [62]:
# 对角阵
np.diag([1,2,3,4,5])
Out[62]:
In [63]:
np.diag([1,2,3,4,5], k=1)
Out[63]:
矩阵计算¶
In [64]:
A = np.matrix('1 2 3; 4 5 6; 7 8 9')
In [65]:
A * 2
Out[65]:
In [66]:
A + 2
Out[66]:
In [67]:
A * A
Out[67]:
In [68]:
# 求模
np.mod(A, 2)
Out[68]:
In [69]:
A % 2
Out[69]:
$A \times B$
$A / B $
$A^2 \times B$
In [70]:
A = np.array([1.0,6.0,2.0,5.0,8.0,9.0])
B = np.array([6.0,2.0,4.0,7.0,9.0,2.0])
A*B, A/B, A**2*B
Out[70]:
向量化函数¶
In [71]:
a = np.array([-3,-2,-1,0,1,2,3])
def Theta(x):
if x >= 0:
return 1
else:
return 0
In [72]:
Theta(a)
In [73]:
Theta_V = np.vectorize(Theta)
Theta_V(a)
Out[73]:
多项式¶
$3x^2+2x-1$
In [74]:
p = np.poly1d([3, 2, -1])
In [75]:
p(1)
Out[75]:
In [76]:
p.roots
Out[76]:
In [77]:
p.order
Out[77]:
In [78]:
x = np.linspace(0, 1, 20)
y = np.sin(x) + 0.3*np.random.rand(20)
p = np.poly1d(np.polyfit(x, y, 3))
t = np.linspace(0,1,200)
plt.plot(x, y, 'o', t, p(t), '-')
Out[78]:

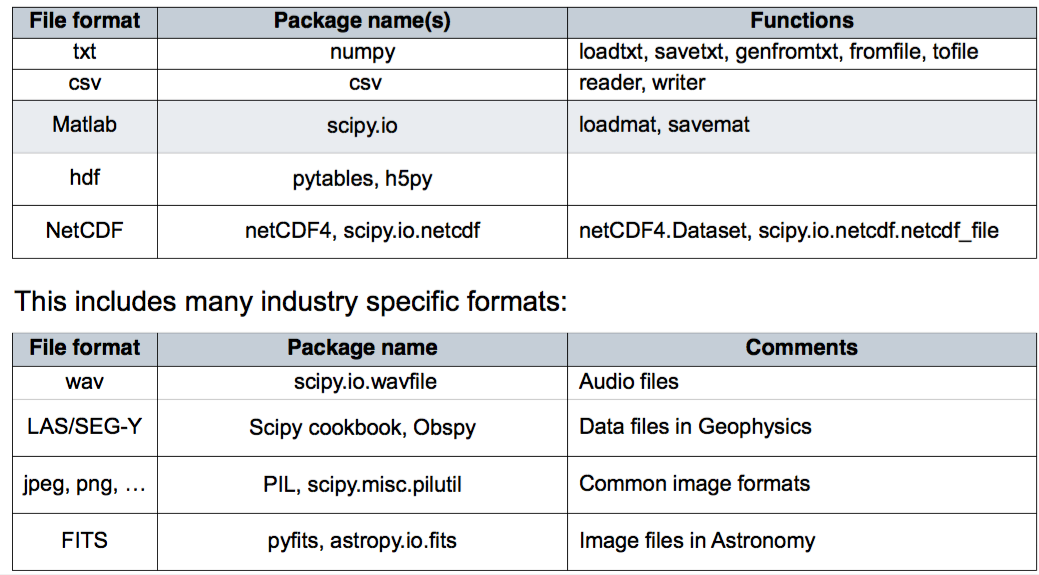
数据文件读取¶
In [79]:
data = []
with open('data/mat.txt') as file:
for line in file:
fields = line.split()
row_data = [float(x) for x in fields]
data.append(row_data)
data = np.array(data)
data
Out[79]:
In [80]:
data = np.loadtxt("data/mat.txt")
data
Out[80]:
In [81]:
M = np.random.rand(10, 4)
np.savetxt("data/mat.txt", M)
In [82]:
M
Out[82]:
In [ ]:
In [83]:
np.savetxt("data/mat.csv", M, fmt="%.3f")
In [84]:
!cat data/mat.csv
In [85]:
dr1 = np.loadtxt('data/sample.txt')
dr1
In [86]:
help(np.loadtxt)
In [87]:
!head data/sample.txt
In [88]:
dr1 = np.loadtxt('data/sample.txt', delimiter="|", skiprows=1)
dr1
In [89]:
!cat data/sample2.txt
In [90]:
dtype = np.dtype([('obsid', 'S6'), ('designation', 'S19'), ('obsdate', 'S10'), ('lmjd', int)])
dr1 = np.loadtxt('data/sample2.txt', dtype=dtype, delimiter="|", skiprows=1)
dr1
Out[90]:
In [91]:
dr1['lmjd']
Out[91]:
In [92]:
# 一元ufunc
arr = np.arange(10)
np.cos(arr)
Out[92]:
In [93]:
# 二元ufunc
x = np.random.randn(10)
y = np.random.randn(10)
x, y
Out[93]:
In [94]:
np.add(x, y)
Out[94]:
In [95]:
## 自定义
def sqrt2(x,y):
return np.sqrt(x**2 + y**2)
# input: 2, output: 1
sqrt2_uf = np.frompyfunc(sqrt2, 2, 1)
sqrt2_uf(x,y)
Out[95]:
In [96]:
sqrt2_uf2 = np.vectorize(sqrt2, otypes=[np.float64])
sqrt2_uf2(x,y)
Out[96]:
结构化数组¶
各列的数据类型可能不一致
In [97]:
dtype=[('RA', np.float64), ('Dec', np.float64), ('Type', np.int16)]
sarr = np.array([(1.23293, 23.231234, 12), (12.3242, 332.47876, 34)], dtype=dtype)
sarr
Out[97]:
In [98]:
sarr['RA']
Out[98]: